
KoBART Summarization (2/3)
지난 포스팅에 이어 추가적인 데이터 처리에 대한 내용을 적을 것이다.
Clone
KoBART-summarization에서 제공하고 있는 뉴스 데이터를 함께 사용하기 위해 우선 클론을 진행해준다.
1
git clone https://github.com/seujung/KoBART-summarization.git
진행에 앞서 필요한 패키지를 설치하기 위한 코드를 작성해주었다.
디렉토리 이동
1
cd /content/drive/MyDrive/KoBART-summarization필요 패키지 설치
1
pip install -r requirements.txt
토치, 토치비전 버전 세팅 (코랩 환경에서 사용했다.)
1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 -f https://download.pytorch.org/whl/torch_stable.html
데이터 처리
KoBART-summarization/data 내의 train, test 데이터의 압축을 해제한다.
1
2
3
4
5
# 클론한 파일 제공 데이터
%cd data
!tar -zxvf train.tar.gz
!tar -zxvf test.tar.gz
!ls
압축이 잘 해제되었다면 train.tsv, test.tsv 파일이 프린트될 것이다.
1
2
3
# 파일 확인
!cat train.tsv
!cat test.tsv
파일을 한번 확인해본다.
1
2
3
4
5
6
# 추가할 데이터를 현재 커널로 가져온다.
import shutil
# train
shutil.copy("/content/drive/MyDrive/Data/law/train.tsv", "/content/drive/My Drive/KoBART-summarization/data/law_train.tsv")
# valid(test)
shutil.copy("/content/drive/MyDrive/Data/law/valid.tsv", "/content/drive/My Drive/KoBART-summarization/data/law_test.tsv")
학습할 데이터를 merge하기 위해 클론한 파일 외 이전 포스팅에서 가공한 데이터를 가져온다.
1
2
3
4
# 데이터 가공을 위해 DataFrame으로 읽어들인다. (최초 1회)
import pandas as pd
df_train = pd.read_csv('law_train.tsv', sep='\t')
df_valid = pd.read_csv('law_test.tsv', sep='\t')
데이터를 한번 확인해보자.
1
df_train.head(3)
Output

가져온 DataFrame을 그대로 사용하면 안된다. (자바로 가공한 코드를 바로 클론한 파일의 데이터와 합쳐 학습 시에도 오류가 났고, DataFrame으로 가져와 합쳐도 오류가 났다. 왜 계속 오류가 날까 3일정도 고민했다. 문득 가공 시 널값을 처리했나?하는 생각을 했는데, 역시 안했다… 지금 진행해야겠다……ㅜ)
Null 값 제거
null 값 여부 확인
1
df_train.isnull().sum(axis = 0)
Output
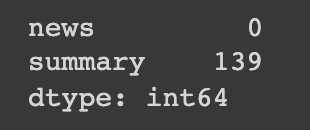
1
df_valid.isnull().sum(axis = 0)
Output
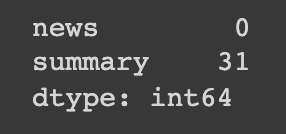
역시나 널값이 존재하는 것을 확인할 수 있다.
dropna
1
2
df_train = df_train.dropna(axis=0)
df_valid = df_valid.dropna(axis=0)
널 값을 제거했다. 잘 제거되었는지 확인해보려면 위에서 null 값 여부 확인을 위해 사용한 코드를 입력하면 된다.
일단 학습이 잘 돌아가니 추가적인 데이터 처리는 끝내야겠다.
Merge
1
2
df_train.to_csv("/content/drive/My Drive/KoBART-summarization/data/train.tsv", mode='a', header=0, sep='\t', index=False)
df_valid.to_csv("/content/drive/My Drive/KoBART-summarization/data/test.tsv", mode='a', header=0, sep='\t', index=False)
위에서 처리한 DataFrame을 기존 tsv 파일과 합치는 코드이다.
append 모드, tsv 파일을 위한 seperator를 사용한다. 기존 파일엔 index 없이 news, summary 열만 가졌으니 index를 False로 설정한다.
👋👋👋 모델 학습 및 테스트는 다음 포스팅에서 진행하겠다. 😀
Comments powered by Disqus.