
KoBART Summarization (1/3)
ai-hub의 법률 뉴스 요약 데이터를 사용해 KoBART 학습을 진행해보려 한다.
예시

KoBART-summarization 깃허브에 제시된 요약 실행 결과 예시
깃허브 링크 : KoBART-summarization
데이터
AI-Hub에서 제공하는 문서요약 텍스트를 사용할 것이다.
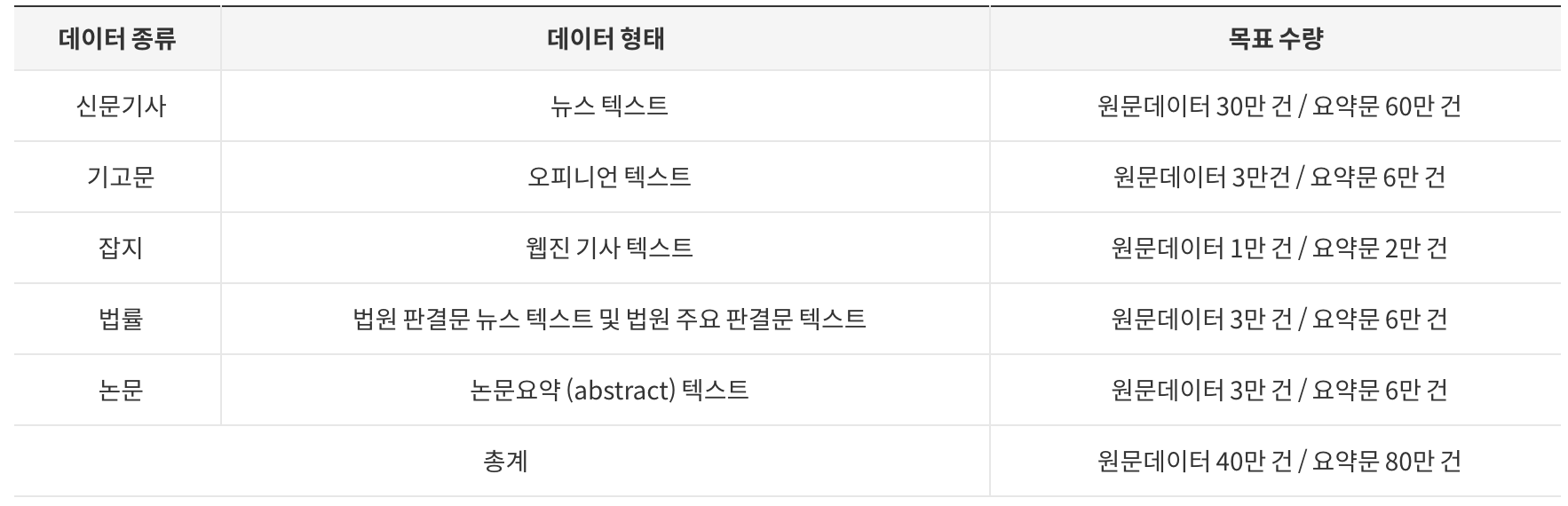
신문, 잡지, 판결문, 논문 등 여러 텍스트 데이터들의 요약본을 제공하고 있다.
KoBART 데이터 형태
AI-Hub를 통해 제공받은 요약 텍스트를 사용하기 위해서 KoBART 학습에 맞는 가공이 필요하다.
먼저, KoBART에서 사용하는 데이터는 train.tsv, test.tsv다.
각 tsv 파일은 news, summary 열로 구성되어 있다.
- news : 원본 텍스트
- summary : (생성)요약 텍스트
위 구성에 맞춰 데이터를 가공해보자!
데이터 가공
사용하지 않을 데이터는 제외하고 데이터의 구조를 살펴보면,
- tsv file
- documents
- text
- 문장 별로 나뉜 원본 텍스트
- abstractive(생성 요약본)
- text
- documents
과 같은 구조로 볼 수 있다.
원본 텍스트는 추출 요약(본 프로젝트에서는 생성 요약을 사용함)을 위해 문장 별로 나눠져있기 때문에 이를 합쳐주는 과정이 필요하다.
- 생성 요약본을 가져오는 작업이 필요하다.
- 과정 1, 2를 모든 document에 적용해 tsv 파일을 생성한다.
위 1, 2, 3 과정은 Java를 통해 진행했다. (이 과정만 Java로 진행했다. 나머지는 Python으로 진행)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public ArrayList<ArrayList<String>> ReadJsonFile(String path) throws IOException, ParseException {
JSONParser parser = new JSONParser();
Reader reader = new FileReader(path);
JSONObject jsonObject = (JSONObject) parser.parse(reader);
JSONArray documents = (JSONArray) jsonObject.get("documents");
ArrayList<ArrayList<String>> result = new ArrayList<ArrayList<String>>();
System.out.println("Read Start!!!!");
for (int i=0; i < documents.size(); i++) {
ArrayList<String> temp = new ArrayList<>();
JSONObject document = (JSONObject) documents.get(i);
// 생성요약
JSONArray abstractive = (JSONArray) document.get("abstractive");
String strAbstractive = (String) abstractive.get(0);
// 원본
JSONArray jsonText = (JSONArray) document.get("text");
jsonText = (JSONArray) jsonText.get(0);
StringBuffer sb = new StringBuffer();
for (int j = 0; j < jsonText.size(); j++) {
JSONObject text = (JSONObject) jsonText.get(j);
String sentence = (String) text.get("sentence");
sb.append(sentence + " ");
}
String originalText = sb.toString();
temp.add(originalText);
temp.add(strAbstractive);
result.add(temp);
String progress = String.format("%.0f", (((i + 1) / (double) documents.size()) * 100));
System.out.println(progress + "%");
}
System.out.println("Read End!!!!");
return result;
}
Json 파일을 parsing 하고, 각 객체에 대한 추출을 적용한 코드이다.
document 별 생성요약본과 원본텍스트를 추출한다.
해당 함수가 실행되면 ArrayList<ArrayList
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public void writeTsvFile(String path, ArrayList<ArrayList<String>> docs) {
try {
BufferedWriter fw = new BufferedWriter(new FileWriter(path, true));
fw.write("news" + "\t" + "summary");
fw.newLine();
for (ArrayList<String> doc : docs) {
String originalText = (String) doc.get(0);
String abstractiveText = (String) doc.get(1);
fw.write(originalText + "\t" + abstractiveText);
fw.newLine();
}
fw.flush();
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
ReadJsonFile를 통해 반환받은 결과를 입력으로 사용한다.
KoBART에서 사용하는 구성에 맞게 column을 설정해 tsv 형식의 파일로 저장한다.
👋👋👋 남은 데이터 가공은 다음 포스팅에서~
Comments powered by Disqus.